Original Link: https://www.anandtech.com/show/6857/amd-stuttering-issues-driver-roadmap-fraps
AMD Comments on GPU Stuttering, Offers Driver Roadmap & Perspective on Benchmarking
by Ryan Smith on March 26, 2013 2:28 AM EST
For as long as I can remember talking about video cards and GPU performance at AnandTech, there has been debate over the type of benchmarks used to represent that performance. In the old days, the debate was mostly manufacturer driven. Curiously enough, the discourse usually fired up when one manufacturer was at a significant deficit in GPU performance. NVIDIA made a big deal about moving away from timedemos and average frame rates during the early GeForce FX (NV30) days, when its cards might have delivered a decent gaming experience but were slaughtered in most benchmarks. Even Intel advocated for a shift away from most CPU bound gaming benchmarks back during the early years of the Pentium 4 - again, for obvious reasons.
It’s a shame that these revolutions in gaming performance testing were always associated with underperforming products (and later dropped once the product stack improved in the next generation or two). It’s a shame because there has always been merit in introducing additional metrics in order to provide the most complete picture when it came to gaming performance.
The issue lay mostly dormant over the past several years. Every now and then there’d be a new attempt to revolutionize GPU performance testing, but most failed to gain widespread traction for one reason or another. Broad repeatability, one of the basic tenets of the scientific method, was usually cast aside in pursuit of a lot of these new attempts at performance testing - which ultimately limited acceptance.
A year and a half ago, Scott Wasson over at the Tech Report did something no one since Dr. Pabst was able to do: he actually brought about a revolution in the 3D game benchmarking scene.
The approach seemed ridiculously simple - we’ve all had the tools for so very long. Scott used FRAPS to record frame times, and would calculate how long every frame in a benchmark took to render. By focusing on individual frame latencies, Scott’s method could better characterize the little hiccups and stutters that would get smoothed out in an average frame rate. With the new method came a bunch of nifty graphs, and the world changed.
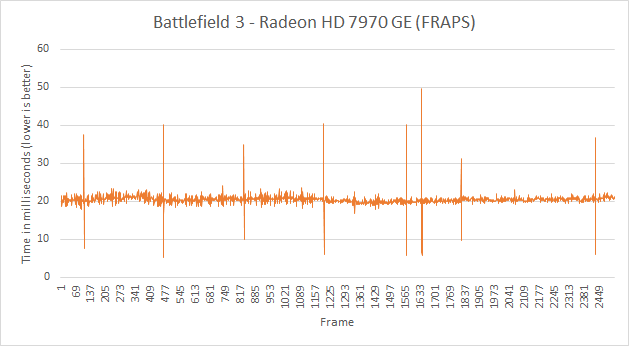
The methodology wasn’t perfect, as FRAPS lacks a holistic view of the 3D rendering pipeline, but it did reveal some surprising issues (in addition to spawning further work that uncovered even more issues on the multi-GPU front). Interestingly enough, many of the issues uncovered by this focus on frame times/latency seemed to primarily impact AMD hardware.
AMD remained curiously quiet as to exactly why its hardware and drivers were so adversely impacted by these new testing methods. While our own foray into evolving GPU testing will come later this week, we had the opportunity to sit down with AMD to understand exactly what’s been going on.
Although neither strictly a defense nor merely an explanation of what we’ve been seeing over the past year, AMD wanted to sit down and better explain their position. This includes both why AMD’s products have been impacted in the manner they were, and why at the same time (and not unlike NVIDIA) AMD is worried about FRAPS being given more weight than it should be. Ultimately AMD believes that it’s to the benefit of buyers and journalists alike to better understand just what is happening, why it’s happening, and just what the most common tools can and are measuring.
What follows is based on our meeting with some of AMD's graphics hardware and driver architects, where they went into depth in all of these issues. In the following pages we’ll get into a high-level explanation of how the Windows rendering pipeline works, why this leads to single-GPU issues, why this leads to multi-GPU issues, and what various tools can measure and see in the rendering process.
The Start: The Rendering Pipeline In Detail
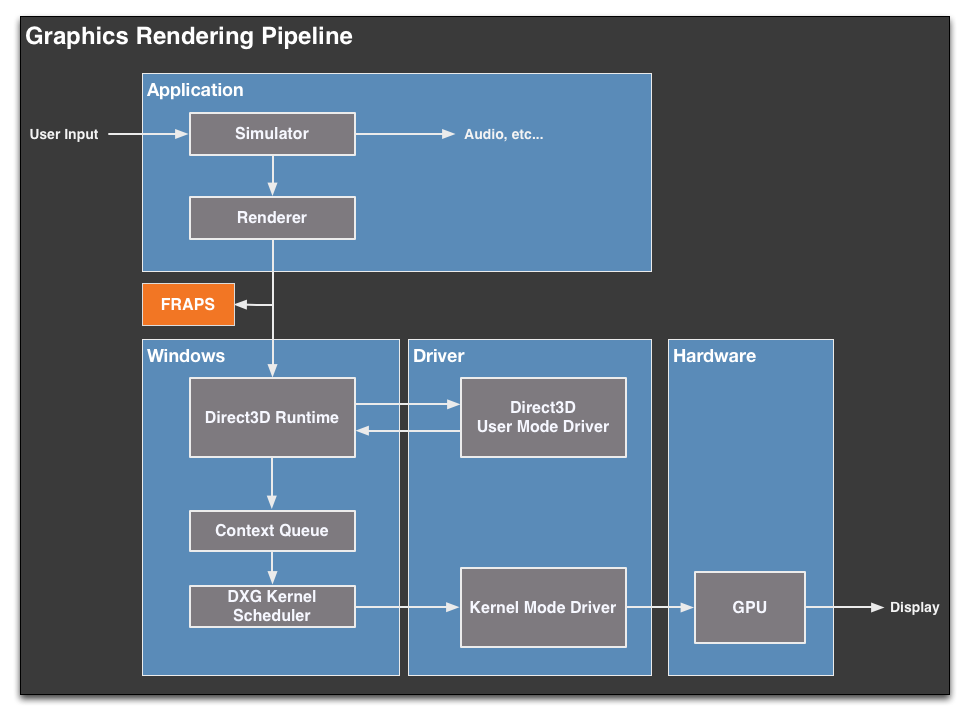
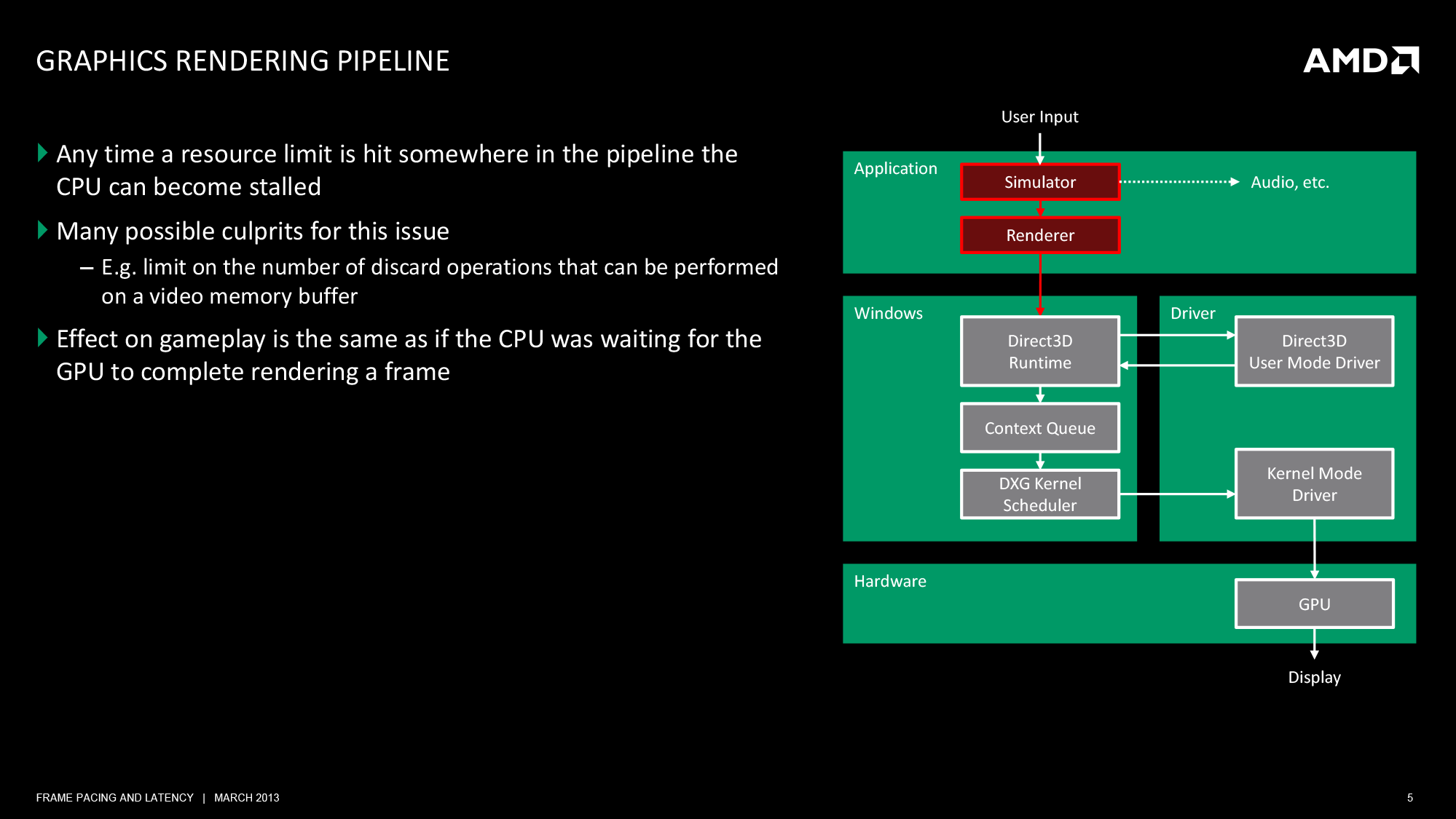
Before we can even discuss the concept of stuttering and other frame timing anomalies, we need to first take a look at a high-level overview of the Windows rendering pipeline. The pipeline isn’t particularly complex, but understanding where various stages of the process are in the hands of Windows, the CPU, the driver, and the video card is necessary to understand where bottlenecks and delays can occur.
At its most fundamental level, rendering a frame is a 3 part process. An application needs to pass data to Windows, Windows needs to manage the process and interface with the drivers, and finally once Windows and driver preparation is complete, a frame can be passed off to the GPU for final rendering and display.
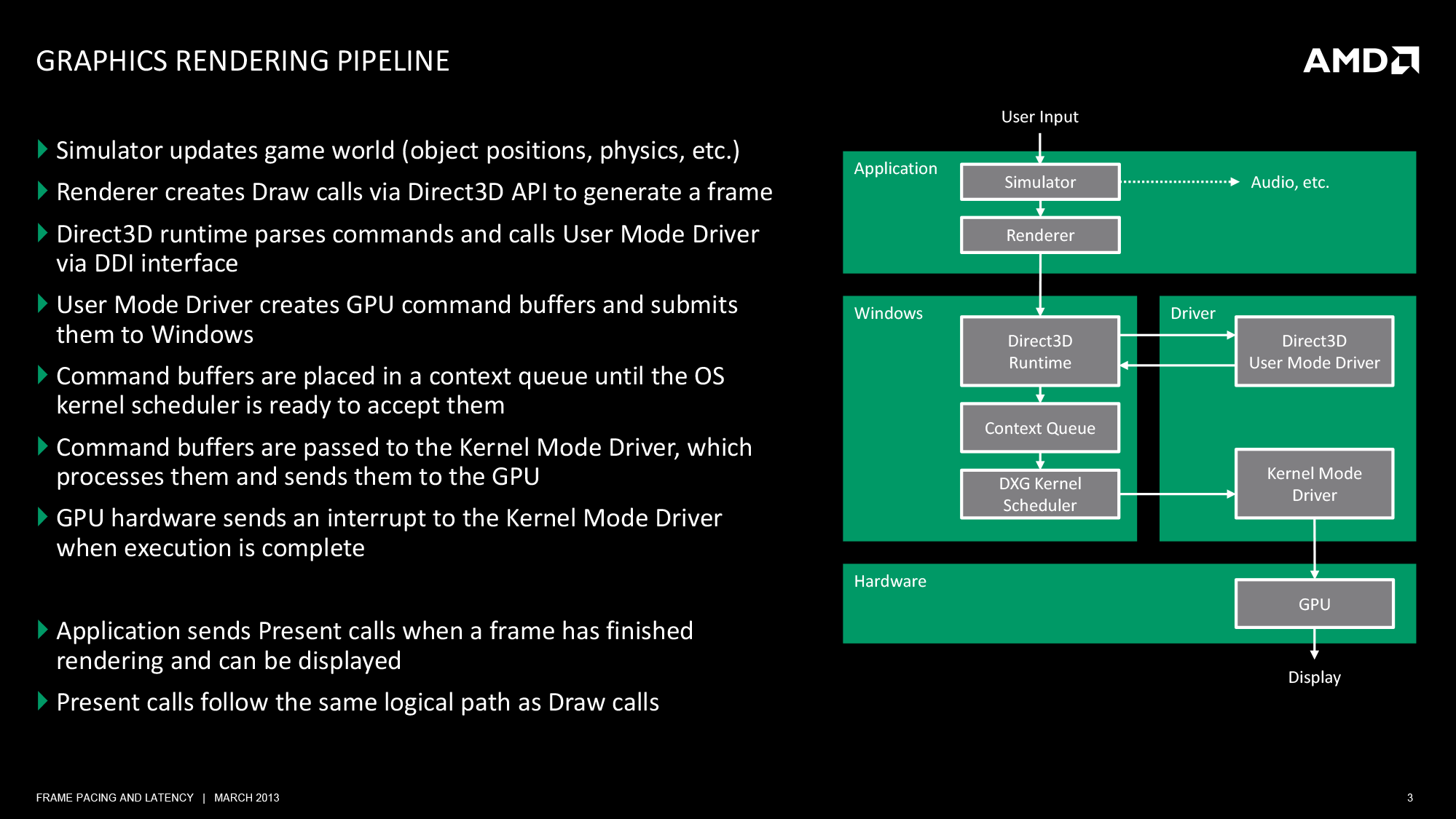
At the top of the chain is the application itself. This is where user input is being handled and where in the context of a game the simulation is being executed. From a technical perspective, it is the application that is the first arbitrator for game smoothness; applications are responsible for adjusting the simulation rate in order to keep the flow of frames smooth. If the application cannot ensure an even rate, then nothing else that follows will really matter.
The reality of course is that this is harder than it sounds. It is not an insurmountable problem, but PCs are devices with a wide spectrum of performance and capabilities. A dual-core processor with an iGPU performs very different from a hex-core processor with a small army of GPUs, and an application needs to be able to accommodate this so that the simulation operates as evenly as possible in both CPU and GPU-bottlenecked scenarios.
Ultimately any timing model is going to be reactive, adjusting itself in response to prior events and how long previous frames took to render. Though another option is to shortcut this process entirely and operate at a fixed (or capped) simulation rate, either basing a game around 30Hz/60Hz operation, or decoupling rendering from the simulation entirely. Anyone who has uncapped id Software’s Rage for example will find that the game simply does not behave correctly without its 60Hz cap.
Static or dynamic, once a simulation has a suitable timing model in place we can then begin to look further down the chain, which is where we first encounter Direct3D, Windows’ primary 3D rendering API. Direct3D is nothing short of an enormous, complex structure of API calls and features. We tend to reduce it to version numbers and marque features for the sanity of ourselves and our readers – as we will here – but it goes without saying that Direct3D takes years to master; and for a GPU manufacturer it’s made all the more complex by the simultaneous existence of the modern iteration of Direct3D (DX10+), and the classic iteration that is DX9 and its predecessors.
For the purpose of the rendering pipeline Direct3D has a few different jobs. First and foremost, it is collecting draw calls from the application, combining them, and processing them for further work. Once a complete frame’s worth of draw calls has been collected, Direct3D passes its processed work over to the first component of the video card driver stack, the User Mode Driver (UMD).
It’s the UMD that is primarily responsible for taking the output of Direct3D and turning it into work batches the GPU can handle. These work batches, command buffers (aka Display Lists), are collections of instructions and data suitable for processing by the target GPU. Among other things, the UMD is responsible for shader compilation and assigning rendering elements to the correct (and best) surface formats for the GPU.

A logical view of single command buffer; from Microsoft's Direct3D documentation
When the UMD’s work is complete, it passes its command buffer back over to Direct3D. Direct3D in turn passes that command buffer to the context queue, our first real bottleneck. We’ll get back to why this is a bottleneck in a bit, but briefly, the context queue is responsible for queuing the individual command buffers in order to smooth out the rendering process. Queuing command buffers at this stage increases frame rendering latency, but by providing a buffer of buffers it allows the rendering pipeline to absorb any variances in rendering time or simulation time to more smoothly render frames.
The context queue has also gone by other names over the years, such as the flip queue and the pre-rendered frames queue. This is the source of the 3 frame render-ahead limit in Windows that is sometimes exposed in games and drivers, as Windows will by default queue up to 3 frames in this manner. This can be controlled by application developers, but most will leave it at 3 so long as a game is smoothly moving along.
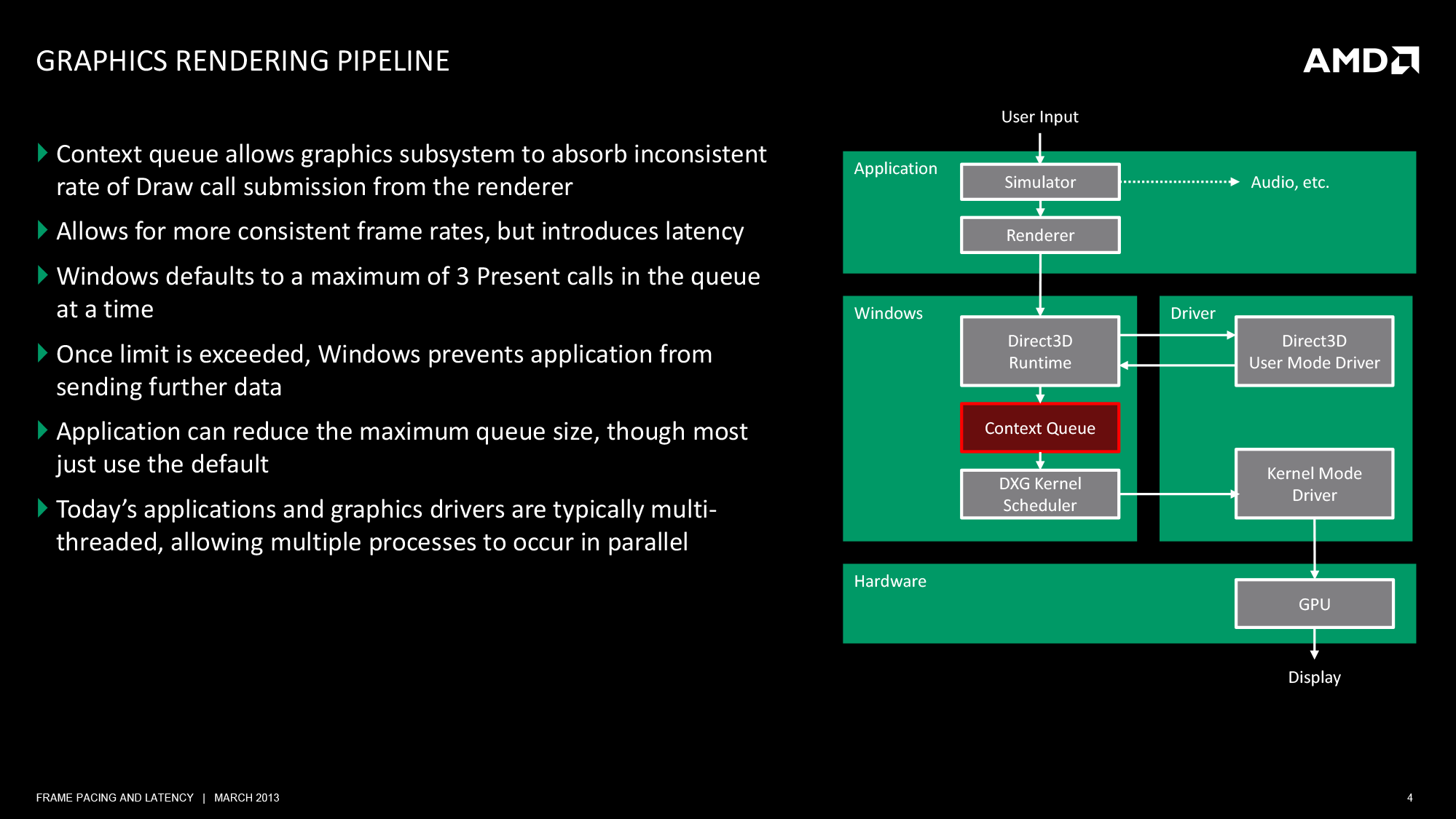
Beyond the context queue we have Windows’ GPU scheduler, which is what regulates the popping of command buffers off of the context queue to be fed to the kernel mode GPU driver (KMD). Beyond this point the rest of the pipeline is rather simple, with the KMD taking the command buffer and feeding it to the GPU, all the while the KMD and GPU work together to manage the operation of the GPU. When a frame is finally completed, the GPU generates an interrupt to inform the KMD and OS about the completion.
At the end of this process we have a rendered frame sitting in the GPU’s back-buffer, but the frame itself is not displayed automatically. At the end of a batch of command buffers – effectively making the beginning and ends of frames – is the Direct3D Present() call. Present is the command that is responsible for telling the GPU to flip the back buffer to the front and to present the rendered frame to the user. Only once the Present call executes does a frame get displayed. The Present call, though not a command buffer object, still follows the same rendering path as the command buffers, including queuing up in the Context Queue.
Just What Is Stuttering?
Now that we’ve seen a high-level overview of the rendering pipeline, we can dive into the subject of stuttering itself.
What is stuttering? In practice it’s any rendering anomaly that occurs that causes the time between frames to noticeably vary. This is admittedly a very generic definition, but it’s also a definition necessary to encompass all the different causes of stuttering.
We’ll get into specific scenarios of single-GPU and multi-GPU stuttering in the following pages, but briefly, stuttering can occur at several different points in the rendering pipeline. If the GPU takes longer to render a frame than expected – keeping in mind it’s impossible to accurately predict rendering times ahead of time – then that would result in stuttering. If a driver takes too long to prepare a frame for the GPU, backing up the rendering pipeline, that would result in stuttering. If a game simulation step takes too long and dispatches a frame later than it would have, or simply finds itself waiting too long before Windows lets it submit the next frame, that would result in stuttering. And if the CPU/OS is too busy to service an application or driver as soon as it would like, that would result in stuttering. The point of all of this being that stuttering and other pacing anomalies can occur at different points of the rendering pipeline, and become the responsibility of different hardware and software components.
Complicating all of this is the fact that Windows is not a real-time operating system, meaning that Windows cannot guarantee that it will execute any given command within a certain period of time. Essentially, Windows will get around to it when it can. In order to achieve the kind of millisecond level response time that applications and drivers need to ensure smoothness, Windows has to be overprovisioned to make sure it has excess resources. Consequently this is part of the reason for why the context queue exists in the first place, to serve as a buffer for when Windows can’t get the next frame passed down quickly enough.
Ultimately, while Windows will make a best-effort to get things done on time, the fact of the matter is that between the OS and the fact that PCs are composed of widely varied hardware, the software/hardware stack makes it virtually impossible to eliminate stuttering. Through careful profiling an optimizations it’s possible to get very close, but as the PC is not a fixed platform developers cannot count on any frame or any specific draw call being completed within a certain amount of time. For that kind of rendering pipeline consistency we’d have to look towards fixed platforms such as game consoles.
Moving on, stuttering is usually – though not always – a problem particular to gaming with v-sync disabled. When v-sync is enabled it places a hard floor on how often frames are presented to the user. For a typical 60Hz monitor this would mean there would be an interval of no shorter than 16.6ms, and in multiples of 16.6ms beyond that.
The significance of this is that if a game can consistently simulate and render at more than 60fps, v-sync effectively limits it to 60fps. With the end result being that the application is blocked from submitting any further frames once the context queue fills up, until the next scheduled frame is displayed. This fixed 16.6ms cycle makes it very easy to schedule frames and will typically minimize any stuttering. Of course v-sync also adds latency to the process since we’re now waiting on the GPU buffer to swap.
Throwing a few more definitions out before we move on, it’s important we differentiate between latency and the frame interval. Though latency gets thrown around as the time between frames, within the world of computer science and graphics that is not accurate, as latency has a different definition. Latency in this case is how long the entire rendering pipeline takes from start to end – from the moment the user clicks to the moment the first frame showing a response is displayed to the user. Most readers are probably more familiar with this concept as input lag, as latency in the rendering pipeline is a significant component of input lag.
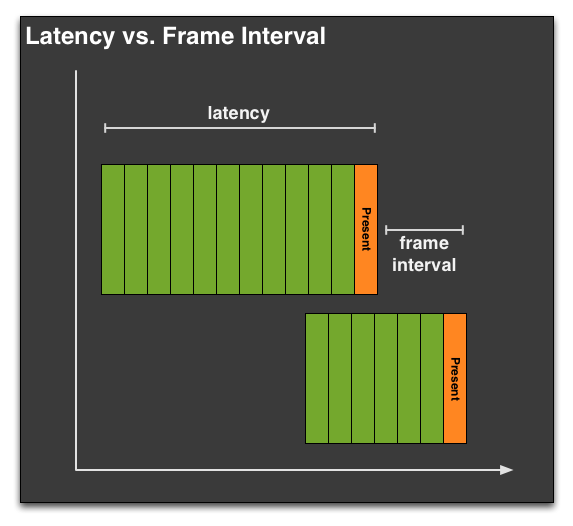
Latency is closely related to, but not identical to the frame interval. Unlike latency, the frame interval is merely the time between frames, typically defined as the time (interval) between frames being displayed at the end of the rendering pipeline by the GPU performing a buffer swap. Typically latency and the frame interval are closely related, but thanks to the context queue it’s possible (and sometimes even likely) for a frame to go through the rendering pipeline with a high latency, while still being displayed at a consistent frame interval. For that matter the opposite can also happen.
When we’re looking at stuttering, what we’re really looking at is the frame interval rather than the latency. It’s possible to measure the latency separately, but whether it’s a software tool like FRAPS or something brute-force such as using a high-speed camera to measure the time between frames, what we’re seeing is the frame interval or a derivation thereof. The context queue means that the frame interval is not equivalent to the latency.
Finally, in our definition of stuttering we also need to somehow define when stuttering becomes apparent. Like input lag and other visual phenomena, there exists a point where stuttering is or isn’t visible to any given user. As we’ve already established that it’s virtually impossible to eliminate stuttering entirely on a variable platform like the PC, stuttering will always be with us to some degree, particularly if v-sync is disabled.
The problem is that this threshold is going to vary from person to person, and as such the idea of what an acceptable amount of stuttering would be is also going to vary depending on who you ask. If a frame takes 5ms longer than the previous, is that going to be noticeable? 10ms? 30ms? And what if this is at 30fps versus 60fps?
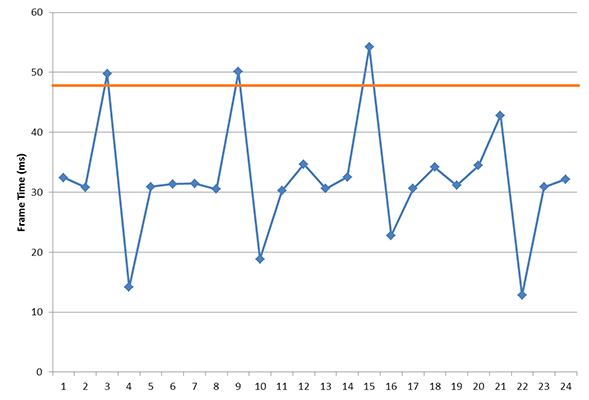
The $64K question: where is the cutoff for "good enough" stutter?
In our discussion with AMD, AMD brought up a very simple but very important point: while we can objectively measure instances of stuttering with the right tools, we cannot objectively measure the impact of stuttering on the user. We can make suggestions for what’s acceptable and set common-sense guidelines for how much of a variance is too much – similar to how 60fps is the commonly accepted threshold for smooth gameplay – but nothing short of a double-blind trial will tell us whether any given instance of stuttering is noticeable to any given individual.
AMD didn’t have all of the answers to this one, and frankly neither do we. Variance will always exist and so some degree of stuttering will always be present. The only point we can really make is the same point AMD made to us, which is that stuttering is only going to matter when it impacts the user. If the user cannot see stuttering then stuttering should no longer be an issue, even if we can measure some small degree of stuttering still occurring. Like input lag, framerates, and other aspects of rendering, there is going to be a point where stuttering can become “good enough” for most users.
The Tools of the Trade: FRAPS & GPUView
Now that we have a basic understanding of the rendering pipeline and just what stuttering is, it’s time to talk about the tools that are commonly used to measure these issues. We’ll start with FRAPS, both because FRAPS is well understood by many of our readers and because FRAPS is what brought stuttering to the forefront of review sites in the first place.
AMD, quite bluntly, has a problem with how FRAPS is being used in some cases. To be clear here FRAPS is a wonderful tool, and without it we would be unable to include a number of different games in our hardware reviews. AMD’s problem with FRAPS is not its existence, what it does, or even how it does things. AMD’s problem with FRAPS comes down how it’s interpreted.
To get to that problem, we’re going to have to take a look at how FRAPS measures framerates. Going back to our diagram of the rendering pipeline, FRAPS hooks into the pipeline very early, at the application stage.
By injecting its DLL into the application, FRAPS then serves to intercept the Direct3D Present call as it’s being made to Direct3D. From here FRAPS can then delay the call for a split second to insert the draw commands to draw its overlay, or FRAPS can simply move on. When it comes to measuring framerates and frametimes what FRAPS is doing is to measure the Present calls. Every time it sees a new present call get pushed out, it counts that as a new frame, does any necessary logging, and then passes that Present call on to Direct3D.
This method is easy to accomplish and works with almost any application, which is what makes FRAPS so versatile. When it comes to measuring the average FPS over a benchmark run for example, FRAPS is great because every Present call it sees will eventually end up triggering a frame to be displayed. The average framerate is merely the number of Present calls FRAPS sees, divided by how long FRAPS was running for.
The problem here is not in using FRAPS to measure average framerates over the run of a benchmark, but rather when it comes to using FRAPS to measure individual frames. FRAPS is at the very start of the rendering pipeline; it’s before the GPU, it’s before the drivers, it’s even before Direct3D and the context queue. As such FRAPS can tell you all about what goes into the rendering pipeline, but FRAPS cannot tell you what comes out of the rendering pipeline.
So to use FRAPS in this method as a way of measuring frame intervals is problematic. Considering in particular that the application can only pass off a new frame when the context queue is ready for it, what FRAPS is actually measuring is the very start of the rendering pipeline, which not unlike a true pipe is limited by what comes after it. If the pipeline is backed up for whatever reason (context queue, drivers, etc), then FRAPS is essentially reporting on what the pipeline is doing, and not the frame interval on the final displayed frames. Simply put, FRAPS cannot tell you the frame interval at the end of the pipeline, it can only infer it from what it’s seeing.
AMD’s problem then is twofold. Going back to our definitions of latency versus frame intervals, FRAPS cannot measure “latency”. The context queue in particular will throw off any attempt to measure true frame latency. The amount of time between present calls is not the amount of time it took a frame to move through the pipeline, especially if the next Present call was delayed for any reason.
AMD’s second problem then is that even when FRAPS is being used to measure frame intervals, due to the issues we’ve mentioned earlier it’s simply not an accurate representation of what the user is seeing. Not only can FRAPS sometimes encounter anomalies that don’t translate to the end of the rendering pipeline, but FRAPS is going to see stuttering that the user cannot. It’s this last bit that is of particular concern to AMD. If FRAPS is saying that AMD cards are having more stuttering – even if the user cannot see it – then are AMD cards worse?
To be clear here the goal is to minimize stuttering throughout, and in a bit we’ll see how AMD is doing that and why it was a problem for them in the first place. But AMD is concerned about FRAPS being used in this manner because it can present data that makes stuttering look worse than it is. And in what’s a very human reaction, people pay more attention to bad news than good news; bad data more than good data. Or more simply put, it’s very easy to look at the data FRAPS produces and to see a problem that does not exist. FRAPS doesn’t just lack a good view of the rendering pipeline, but FRAPS data alone doesn’t provide context to decide what data matters and what does not.
Ultimately due to its mechanisms FRAPS is too coarse grained. It doesn’t have a complete picture of the rendering pipeline, and it’s taking readings from the wrong point in the rendering pipeline. In an ideal world we would like to be able to watch a frame in flight from the start to the end; to see what millisecond of a game simulation a frame is from, and to compare that against the frame intervals of successive frames. Baring that we would at least like to see the frame interval at the end of the rendering pipeline where the user is seeing the results, and unfortunately FRAPS can’t do that either.

Adding weight to the whole matter is the fact that FRAPS is one of the few things both AMD and NVIDIA can agree on. In our talks with NVIDIA and in past statements made to the press, NVIDIA dislikes FRAPS being used in this manner for roughly the same reason. The fact that it’s measuring Present calls instead of the time a frame is actually shown to the user impacts them just as well, and muddles the picture when it comes to trying to differentiate themselves from AMD. Again, not to say that NVIDIA thinks FRAPS is a bad tool, but there seems to be a general agreement with AMD’s stance that beyond a certain point it’s the wrong tool for measuring stuttering.
For our part, when we first went into our meeting with AMD we were expecting something a little more standoffish on the matter of FRAPS. Instead what we found was that we were in agreement on the same issues for the same reasons. As you, our readers are quick to point out, we do not currently do frame interval measurements. We do not do that because we do not currently have any meaningful tools to do so beyond FRAPS, for which we have known for years now about how it works and its limitations. There are tools in development that will change this, and this is something we’re hopefully going to be able to talk about soon. But in the meantime what we will tell you is the same thing AMD and NVIDIA will tell you: FRAPS is not the best way to measure frame intervals. There is a better way.
Finally, though we’ve just spent a great deal of time talking about FRAPS’ shortfalls when it comes to measuring frame intervals, we’re not going to dismiss it entirely. FRAPS may be a coarse tool, but even a coarse tool is going to catch big problems. And this is exactly what Scott Wasson and other reviewers have seen. At the very start of this odyssey AMD’s single-GPU frame interval problem was so bad that even FRAPS could see it. FRAPS did in fact “bust” AMD as it were, and for that AMD is even grateful. But as AMD resolves their problems and moves on to finer grained problems, the tools need to become finer grained too. And FRAPS as it currently is cannot make that jump.
GPUView
While we’ve spent most of our discussion on tools discussing FRAPS and why both AMD and NVIDIA find it insufficient, there are other tools out there. AMD and NVIDIA of course have access to far better tools than we do, and people with the knowledge to use them. This includes their internal tools, tools that are part of their respective SDKs, and other 3rd party tools.
AMD’s tool of choice here actually comes from Microsoft, and it’s called GPUView.
GPUView is a GPU performance profiling tool, and it gives very near a top-to-bottom overview of the rendering pipeline. GPUView can see the command buffers, the Present calls, the context queue, the CPU utilization of various threads, the drivers, and more. In fact short of being able to tell us the simulation time, GPUView is the kind of massive data dump a GPU developer, programmer, or even reviewer could ever want.
The only problem with GPUView is that it’s incredibly complex. We’ve tried to use it before and we’re simply overwhelmed with the data it provides. Furthermore it still doesn’t show us when a GPU buffer swap actually takes place and the user sees a new frame, and that remains the basis of any kind of fine-grained look into stuttering. Ultimately GPUView is a tool meant for seasoned professionals and it shows.
So why bring up GPUView at all? First and foremost, it’s one of the same tools AMD is using. Understanding something about the tool they use will bring us closer to understanding how they are (or are not) identifying problems in order to fix them. The second reason is that GPUView can show us in practice what up until now we’ve discussed only in theory: where some of the bottlenecks are in the GPU rendering process that lead to stuttering.

AMD’s presentation to use included two slides on GPUView, which in turn we’re including in this article. The first slide is of Crysis 3, and in it we can see a number of frames in flight. Notably we can also see the periods where there are several idle CPU threads, showing us there is some GPU bottlenecking going on.
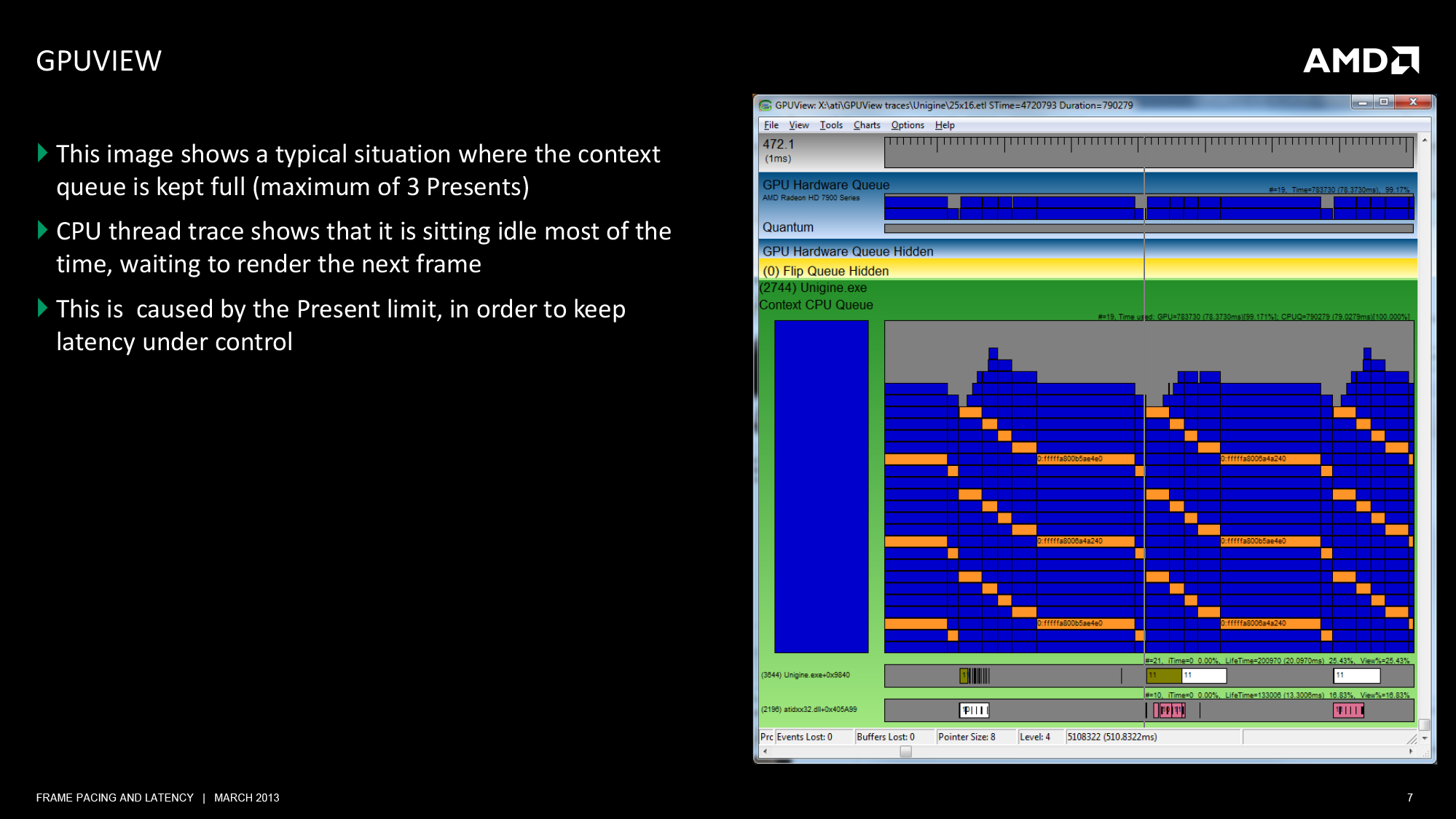
The second slide is of GPUView with Unigine Heaven, presenting us with a textbook situation of where the GPU is the bottleneck, as Heaven is designed from the start to be a GPU benchmark and has limited CPU usage as a result. Of note, we can see the behavior of Heaven as it waits for the context queue to open up to take another frame. Heaven runs with the standard context queue limit of 3, and we can clearly see the 3 Presents, representing the 3 frames in the queue.
Ultimately GPUView is just one of many tools, but it does give us a better idea of what’s occurring in the middle of the rendering pipeline. And in AMD’s case it’s one of the better ways to break down the rendering pipeline and track down the issues that have led to their stuttering problems.
AMD & Single-GPU Stuttering: Causes & Solutions
Thus far we’ve discussed stuttering and the rendering pipeline in theory, and taken a look at an example of the rendering pipeline in practice through GPUView. With a basic understanding of those principles, we can finally get into explaining AMD’s specific situation. Why did AMD have a single-GPU stuttering problem?
The shortest answer also the bluntest answer: AMD had a stuttering problem because AMD wasn’t looking for a stuttering problem. AMD does a great deal of competitive analysis (read: seeing what NVIDIA is doing) on overall performance, but AMD was never doing competitive analysis for stuttering.
Because stuttering is such a complex issue and AMD had such great knowledge into their drivers, AMD assumed that stuttering was occurring due to the applications and the OS, things that were out of their control. Furthermore because those things were out of their control, AMD assumed that they were happening to NVIDIA and Intel GPUs too. After all, there wasn’t any kind of competitive analysis to scientifically confirm this. AMD never saw that NVIDIA cards weren’t experiencing as much stuttering, and consequently never saw that they did in fact have more control over stuttering than they first thought.
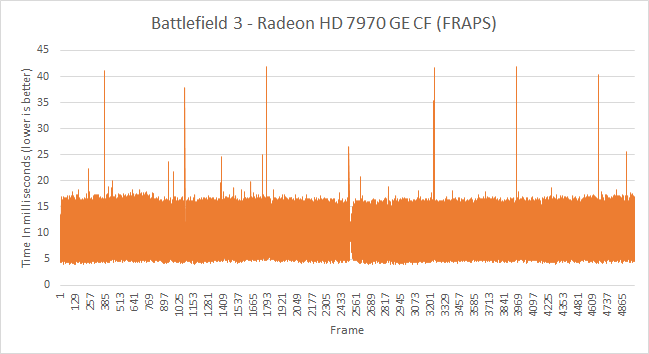
Ultimately it wasn’t until Scott Wasson and other journalists went to work with FRAPS and kept it up that it became obvious to AMD that they had a problem. FRAPS may be a coarse tool, but even it could see some of AMD’s stuttering issues.
Since that time AMD has been hard at work on fixing the issue, producing new driver builds later last year and in the first part of this year to address the issue. AMD’s latest drivers have been fixing bugs, engaging workarounds, and otherwise taking care of this issue so that they can be competitive with NVIDIA when it comes to stuttering.
There is still work to do – AMD quickly fixed their DX9 issues, while DX10 fixes are in the process of being rolled out – but in many ways this is a post-mortem on the issue rather than being an explanation of what AMD will do in the future. Not every game is fixed yet, but many are. Scott Wasson’s most recent results show an incredible improvement for AMD compared to where they were even 6 months ago.
The biggest changes AMD has made from here on out are that they’re now doing competitive analysis on stuttering and they’re explicitly looking for it in their tools, to ensure that stuttering issues don’t return (at least in as much as they are able to control). With many of the bugs and issues that lead to stuttering in the first place already fixed, AMD can use what they’ve learned to analyze future games and try to catch issues before the game is released, or at the very least fix it as quickly as possible.
AMD’s gameplan aside, there are two remaining questions on the subject that need to be dealt with. The first is what happened at a technical level to cause the stuttering in the first place, and what, if anything, can be done about the remaining stuttering.
The answer to the first question is that what went wrong depends on the game. AMD did not go into specific detail about individual games, but they did lay out the types of issues they ran across. For example, resource limits may occur in the application or the driver, triggering a stall that in turn triggers stuttering. Discarding the constant or vertex buffers too often was one such cause of this, as it would mean the driver would need to wait for one of the buffers to actually become freed up before the job could proceed.
Other times the issue was the driver itself misbehaving in a way AMD never expected. In one such case AMD’s driver was sporadically consuming far more CPU time than AMD intended, something AMD never even realized was possible. The end result was yet another block that triggers a stall that triggers stuttering.
Yet still other problems are in the application and the OS itself. As we’ve mentioned before AMD cannot fix these issues because they’re not under AMD’s control, but as it turns out AMD can effectively trick the OS and applications into behaving better. So AMD has implemented workarounds in their drivers for these application/OS issues, which doesn’t strictly fix the problem but will mitigate it.
A recurring theme in all of these issues was that they were easy to fix. It may only take AMD an hour to find the cause of a stuttering instance, and then even less time to make a driver change to deal with it. Stuttering on the whole is still a complex issue, but in AMD’s case they were easy fixes once AMD started looking for the problem.
Perhaps the most interesting thing about this entire process – and the most embarrassing thing for AMD – is not just that stuttering was occurring and they weren’t looking for it, but by not looking for stuttering they were leaving performance on the table. Stuttering doesn’t just impact the frame intervals, but many of those stalls where stuttering was occurring were also stalling the GPU entirely, reducing overall performance. One figure AMD threw around was that when they fixed their stuttering issue on Borderlands 2, overall performance had increased by nearly 13%, a very significant increase in performance that AMD would normally have to fight for, but instead exposed by an easy fix for stuttering. So AMD’s fixing their stuttering has not only resolved that issue, but in certain cases it has helped performance too.
This isn’t to say that AMD can fix all forms of stuttering. As we’ve already discussed, Windows isn’t a real time operating system and the PC platform itself is highly variable. Especially in resource constrained scenarios it’s simply not going to be possible to fix all forms of stuttering. If the CPU gets busy and the Present call from the application gets held up, then there’s nothing AMD can do other than to process it once it does arrive. This is the purpose of the context queue, to help smooth things out at the cost of some latency.
Moving on, though it’s outside the scope of this article for both a lack of time and a lack of tools, we will be looking at stuttering on AMD cards and NVIDIA cards as the necessary tools become available. AMD hasn’t fixed all of their issues yet and they waste no time admitting to it, so we will want to track their progress and see just how far along they are in bringing this issue under control.
Finally, we wanted to spend a bit more time talking about FRAPS in relation to what AMD discovered, and why FRAPS may still see issues that are not present.

The above is what AMD is calling the heartbeat pattern, and it’s something FRAPS is reporting even in some of the games they’ve fixed. This highlights one of the problems with trying to monitor frame intervals based on Present calls, as the context queue is absorbing the uneven frame dispatch, but FRAPS doesn’t realize it.
In a heartbeat situation the next Present gets delayed coming out of the application for whatever reason, which results in the rendering pipeline feeding from the context queue for a bit while nothing new comes in. Eventually the block is cleared and the application submits the next Present, at which point FRAPS records the Present as having come relatively later. Furthermore, since the context queue has been at least partially drained, there’s still room for one more frame, so rather than idling for a bit the application immediately gets to work on the next frame. As a result the next Present hits the context queue sooner than average, resulting in the early frame as picked up by FRAPS.
In this scenario, at the end of the rendering pipeline every frame could be displayed at an even pace despite the unevenness at the input, but FRAPS would never know. This doesn’t mean it’s not an issue, as uneven presents will cause the gap in time between the simulation steps to suddenly become uneven as well. But unless the heartbeat pattern occurs with high regularity or the size of the beat is enough to let the context queue drain completely, the impact from this scenario is far less than having the frames come out of the end of the rendering pipeline unevenly. Ultimately it’s another form of stuttering, but in the case of FRAPS looks far worse than it would be if we were measuring the end of the rendering pipeline and what the user was actually seeing.
AMD & Multi-GPU Stuttering: A Work In Progress
When it comes to stuttering there’s really two classes of stuttering that need to be discussed. The first is single-GPU stuttering as we’ve discussed in the previous pages, where driver issues, application issues, and the context buffer all interact to influence the pace for how frames are doled out before finally being rendered and presented. The second type of stuttering, micro-stuttering, is endemic to multi-GPU configurations. In micro-stuttering on top of all of the other issues encountered with single-GPU stuttering, there are also further variance and frame interval issues introduced due to how multi-GPU configurations split their workloads.
In brief, in multi-GPU setups, be it single-card products like the GTX 690 or multiple cards such as a pair of 7970s, the primary mode of splitting up work is a process called Alternate Frame Rendering (AFR). In AFR, rather than have multiple GPUs working on a single frame, each GPU gets its own frame. This method has over time proven to be the most reliable method, as attempting to split up a single frame over multiple GPUs (with their relatively awful interconnect) has proven to be unreliable and difficult to get working. AFR in contrast is by no means perfect and has to deal with inter-frame dependency issues – where the next frame relies in part on the previous frame – but this is still easier to implement and more consistent than previous efforts at splitting frames.
Moving on, due to the mechanisms of AFR, it can further impact the frame intervals and as a result whether stuttering is perceived. To do AFR well it’s necessary to pace the output of each GPU such that each GPU is delivering a rendered frame at as even a rate as possible; not too soon after the previous frame, and not too late such that the following frame comes up quickly. In a 2 GPU setup, which is going to be the most common, this means the second GPU needs to produce a finished frame when the first GPU is roughly half-way done with its current frame. Should this fail to happen then we have micro-stuttering.
Micro-stuttering has been a longstanding issue on multi-GPU setups. Both NVIDIA and AMD have worked on the issue to various degrees, but at the end of the day multi-GPU setups have never proven to be as reliable as single-GPU setups, which is why our editorial position on the matter has been to always favor single powerful GPUs over multiple GPUs when at all possible. To that end, just as FRAPS has ignited an interest in single-GPU stuttering issues, it has also ignited an interest in multi-GPU stuttering issues.
The bulk of AMD’s presentation – and consequently our own article – has been focused on single-GPU issues. AMD is working on multi-GPU issues too, but the team that is handling microstuttering is not the team we were speaking to. The team we were speaking to is the team that has been handling single-GPU issues. As such AMD’s statements on the matter are meaningful, but brief.
Multi-GPU stuttering has become an important issue for AMD just as single-GPU stuttering has, and AMD is working on a resolution for it. That resolution will come in or around a July driver drop, at which point AMD will introduce some new driver options to control how their cards deal with the issue. In the meantime however micro-stuttering and how AMD’s multi-GPU technology compares to NVIIDA’s multi-GPU technology is likely to become a bigger issue before AMD can push out their new driver. So AMD may be spending the next couple of months on the defensive.
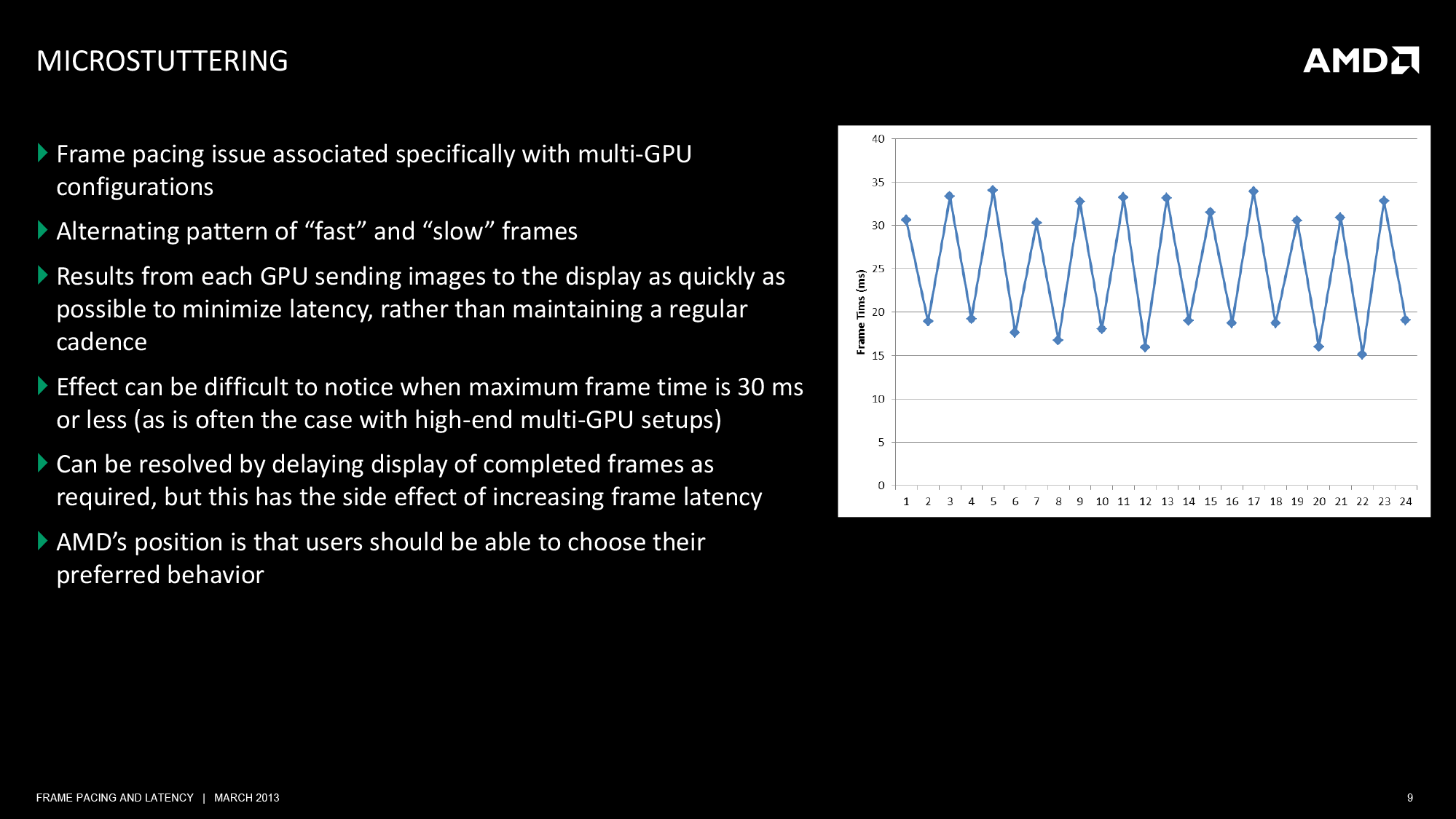
AMD’s current position on micro-stuttering is that they are favoring latency (and not frame intervals) above all else. By keeping their latency low and as even as possible the resulting input lag from multi-GPU setups is reduced, making the experience more responsive for the user. This is a position that’s essentially in alignment with how they’re handling single-GPU stuttering too, but in the single-GPU world there isn’t a deliberate frame pacing aspect to take into consideration since they merely need to render frames as fast as they receive them.
In any case, AMD’s position on the issue has been one where they clearly still think they’re right, but also one where they’re going to lighten up on their position regardless. The alternative approach to favoring latency is to favor the frame interval, which in the case of multi-GPU setups means focusing on frame pacing. By deliberately delaying frames AMD can ensure they arrive more evenly, but in doing so they would increase the latency in the rendering pipeline, and ultimately the latency the user experiences. AMD already does this to some degree, but today it’s not being done explicitly and favored over latency concerns, which is what’s going to change.
In a typical AMD move, AMD will ultimately be leaving this up to the user. In their July driver AMD will be introducing a multi-GPU stuttering control that will let the user pick between an emphasis on latency, or an emphasis on frame pacing. The former of course being their current method, while the latter would be their new method to reduce micro-stuttering at the cost of latency.
We don’t have any more details on this driver or AMD’s frame pacing method at this time, but in our conversation with AMD they didn’t sound like they were worried about having any problems implementing explicit frame pacing, and that it was merely a matter of the process taking a while. Frame pacing itself can cause its own stutter issues – holding back one frame but not another can sometimes make the frame display evenly, but from a simulation step only a few milliseconds after the previous step – but ultimately the pacing process will cause the simulation to try to match the GPU and pace itself accordingly, so it would be a transient issue.
On a final note, more so than even single-GPU stuttering, multi-GPU stuttering is something that unfortunately FRAPS is poorly prepared for. By looking at Present calls it’s completely blind to how the GPU is doing any frame pacing, which means it’s currently difficult to see the impact of frame pacing short of a high-speed camera. As further tools are developed that let us analyze the end of the rendering chain, this will allow us to more properly analyze how frame pacing works and what its true impact on the user is.
Final Words
Bringing things to a close, when AMD first came to us about this, we had mixed feelings about what they were proposing. Typically, manufacturers only take issue with benchmarking methodologies when they have some deficiency on their part. Surprisingly enough, AMD's stance was equal parts recognition of where they had issues and offering their input on the right way to do things.
Meanwhile, we’ve wanted to do an article like this for some time now; specifically a dissection of FRAPS so that we could better explain why we have not been using FRAPS for investigating stuttering. To our surprise, we found AMD repeating many of the positions we held, and more importantly they were offering up further facts and additional data that we didn’t have access to that would help support our own position. So despite whatever AMD’s intentions were, this worked out well for us.
Ultimately AMD’s message has been one of information, explanation, and admission of oversight. AMD has been clear with us from the start that the primary reason they even ended up in this situation is because they weren’t doing sufficient competitive analysis, and that they have revised their driver development process so that they now do this analysis to prevent future problems. The fact that NVIDIA seemed to have figured all of this out much earlier was a point of frustration for AMD. The company likely left non-negligable amounts of performance on the table over the years, which could've definitely helped in close races.
At the same time they’ve been hard at work on fixing existing stuttering problems, with many of those fixes being delivered while fixes for more DX10+ games are right around the corner.
At the same time however AMD’s message is not just one about stuttering, but also one about benchmark and analysis methods with FRAPS. FRAPS, despite its limitations, has clearly exposed problems with AMD’s drivers that resulted in stuttering that AMD needed to fix. Meanwhile measuring frame intervals with FRAPS has become an increasingly common technique in reviews, only to really become popular at the same time as when AMD has finally fixed many of these issues.
AMD’s concern – and one that NVIDIA has shared with them in the past – is that measuring the rendering pipeline at the beginning of the pipeline like FRAPS goes about it does not accurately represent what the end user is seeing, due to the various buffers in the Pipeline and how the Present mechanism works. While FRAPS was good enough to pick up on the major stuttering issues in AMD’s drivers, as these issues get resolved it’s far too coarse a tool to pick up on finer issues, and in fact what FRAPS is now seeing is decoupled from what the user is seeing due to the presence of the context queue and other buffers. All of these, for the record, are points we agreed with AMD on, even before our meeting.
The end result of all of this is that change is in the air. Just as how quickly as Scott Wasson and others changed the nature of GPU reviewing by using FRAPS to measure frametimes, things must change again for GPU reviewers. If FRAPS is no longer an adequate tool to measure stuttering and frame intervals – as both AMD and NVIDIA insist – then new methods and new tools must be created to measure those factors at the end of the rendering pipeline, where the results would match what the end user is seeing. Though on the subject of tools, AMD for their part is favoring double-blind trials as the ultimate method of detecting stuttering. They’re fundamentally right since the perceptibility of stuttering depends on the person, but admittedly this is also the least objective/qualitative way of evaluating stuttering.
In any case, just as how change is in the air for GPU reviews, AMD has had to engage in their own changes too. They have changed how they develop their drivers, how they do competitive analysis, and how they look at stuttering and frame intervals in games. And they’re not done. They’re already working on changing how they do frame pacing for multi-GPU setups, and come July we’re going to have the chance to see the results of AMD’s latest efforts there.
For us this is what we hope to be the start of our own changes. There are tools in development that meet our criteria for better measuring frame intervals, and hopefully in the not too distant future we’ll be able to discuss those tools to a much greater degree, and to use those tools to go about measuring frame intervals in the manner we’ve always wanted to. But that is a story for another day, so until then you’ll have to stay tuned to find out.






